Sorry for folks who were lost last week. This week might not be better. But I’ve only just started writing these, so who knows? Maybe there’ll be good, generally applicable lessons. In general nothing I do feels pliable, but I can’t always tell.
At last our flat has been surveyed, which means the slow march of selling can continue. Everyone so far seems content with the price that we’ve agreed on, so all that remains now is to wait for everything else to happen.
This is true about everything, actually.
I took out an equity loan with the Help To Buy scheme, which means I have to deal with a third-party agency that won the contract from Homes England to administer the scheme. Reading their Trustpilot reviews is…a bad idea, if you have an equity loan. So far my experience has been okay: they told me quickly that one of my forms was wrong, and I was able to get that sorted by the next day. According to GOV.UK, they’ll respond in “7-10” days. It’s been 6 calendar days, or five working days. Stay tuned for good news…I hope.
I’ve done more AWS work! I do plenty in my day job, but my day job doesn’t publish their code, for perfectly sensible reasons. I am publishing all my code for the mentor-matcher, so let’s take a look at that.
The core of this code is something called a State Machine, also known as a finite state machine. Here is a diagram:
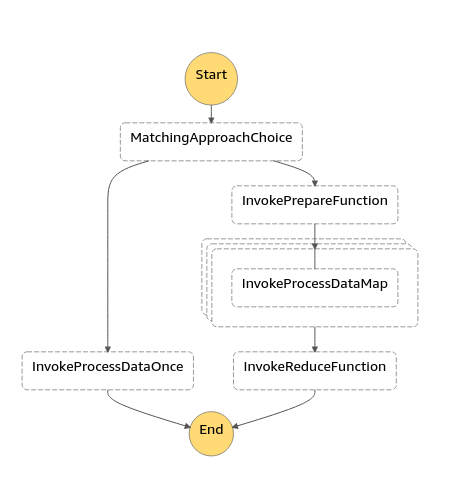
There are a few gotchas I’m finding with AWS. One of these I think is specific to event-driven architectures, which is: events must be small. Small events trigger big things. This leads to some behaviour that I don’t love, such as code like this:
def read_write_s3(function):
@functools.wraps
def wrapped_func(event, context):
data_uuid = event["data_uuid"]
step = event.get("step", 0)
data = s3_resource.Object(bucket_name, f"{data_uuid}/{str(step)}.json")
file_content = data.get()["Body"].read().decode("utf-8")
json_content = json.loads(file_content)
output = function(json_content)
data_for_next_step = s3_resource.Object(
bucket_name, f"{data_uuid}/{str(step + 1)}"
)
data_for_next_step.put(Body=(bytes(json.dumps(output).encode("UTF-8"))))
return {"data_uuid": data_uuid, "step": step + 1}
return wrapped_func
@read_write_s3
def async_process_data_event_handler(event: dict[str, int | list[dict]], context):
"""
Event handler that calls the `tasks.async_process_data` function.
:param event: A dictionary with an event from AWS. Must have the "mentees" and "mentors" keys
:param context: The AWS context
:return:
"""
unmatched_bonus = event.get("unmatched bonus", 6)
mentees = event["mentees"]
mentors = event["mentors"]
matched_mentors, matched_mentees, bonus = async_process_data(
mentors, mentees, unmatched_bonus
)
return {
"mentors": [mentor.to_dict_for_output() for mentor in matched_mentors],
"mentees": [mentee.to_dict_for_output() for mentee in matched_mentees],
"unmatched bonus": bonus,
}
where I’ve written a decorator to deal with the continuous writing-in-and-out of S3, leaving the function to do the single thing I need it to do.
This is a perfectly good approach to take, I just think it’s a bit ugly. But it gets me lots of attention from recruiters, and what boy can say no to that?
(This one. I’ve even updated my profile to tell people I’m happy where I am.)
This code takes great big chunks of data and, when a specific keyword is passed in at the top:
- Creates a number of copies of it
- Applies, or maps, the ProcessData function over each of them
- Aggregates the results and reduces it to a single answer
This approach takes advantage of the immense scalability of the cloud platform to do several million parallel calculations, and then reduce them down to the best solution. It takes about two minutes, and costs about a dollar. Maybe two dollars if it’s real tricky.
